
Feedback on a Large-Scale Big Data Migration

A few years ago, at Société Générale, I had the opportunity to lead a strategic migration program: moving over 100 applications and datalabs from a legacy Big Data cluster to a new, more modern, more automated, and more secure platform… without ever interrupting production. My scope covered the central departments: compliance, operational and credit risks, liquidity, finance, group repositories, and HR.
Today, I am sharing with you the key lessons from this adventure, hoping they will inspire you for your own migration projects, especially towards the Cloud.
Challenge #1: Cracking the Data Subject
The first major challenge was to have a clear vision of how to handle data availability, both for internal teams and for client projects. We initially considered targeted approaches, such as:
- a surgical intervention, imagining making the right data available on the right cluster for the right application at the right time…
- identifying “project clusters” using the same set of data, with the scheduling of these clusters forming our migration plan.
But these two approaches immediately seemed far too complicated and therefore risky given our operational constraints. Thus, we preferred the following approach:
- ensure that data is permanently available on both clusters, all the time, for all authorized consumers.
- thus, shift these data constraints to the technical dimension without burdening the program’s organization and governance: projects then had greater freedom to choose their migration timing independently of their data suppliers’ schedules.
To do this, we quickly launched a product in advance to make our technical synchronization base more flexible, more scalable, and above all, easily usable on a large scale by the migration teams, without requiring low-level interventions on the infrastructure side.
Challenge #2: An Agile and Tooled Migration
From the beginning of the program, we adopted some principles of modern software development:
- putting agility at the heart of the migration team, encompassed within a more standard program organization.
- identifying products capable of evolving in “fail fast” mode and pushing automation and standardization as far as possible. This was to ensure we had completely robust products when scaling up and handling the most critical projects.
More concretely, here is how these two dimensions were implemented.
For the first, the migration team was organized in Scrum with a one-week sprint, a formalized backlog of course, under control during Sprint planning, and with rapid feedback loops thanks to weekly demos and retrospectives. In addition to this agile setup, we had weekly operational committees with the projects and steering committees with management: these instances allowed us to maintain a constant and close link with the many stakeholders.
For the second, we were developing the following products (the BUILD in parallel with the RUN of the migrations):
- a product consisting of the migration pattern (whose Gantt chart is shown below) including its associated deliverables: documentation, onboarding awareness, technical automation tools, etc…
- a product, entrusted to an independent team, to industrialize and secure data synchronizations between clusters and environments (as already mentioned)
- a product dedicated to data injection (the technical details of which are beyond the scope of this article)
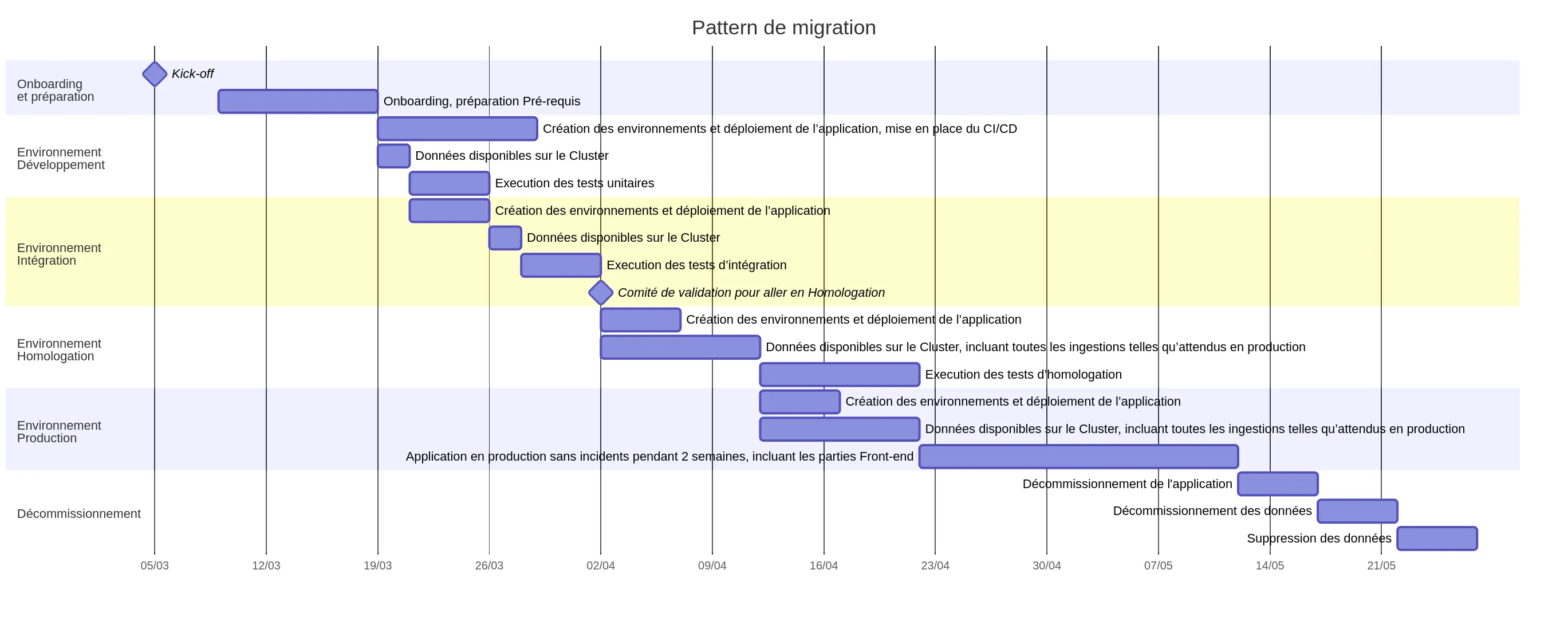
5-Phase Migration Roadmap
On the program management side, we organized our migration roadmap into 5 phases, defined according to the typology (and constraints) of the projects, as described below:
- Phase 1 - Test the Proof of Concept: validate our migration pattern and the proper functioning of the new Cluster in production. The migration of the first project, a relatively modest project but using more than twenty different data sources, allowed us to achieve the objectives of this phase.
- Phase 2 - Scale up: migrate several large, complex projects involving a maximum of technical components external to the Big Data cluster (Talend infrastructures, edge servers around the Cluster, external databases with many flows to open, etc.). We could thus assess our ability to scale up and finalize our migration pattern in vivo.
- Phase 3 - Deliver: during this phase, we benefited from the previous phases by migrating several dozen projects according to our predictions, including all types of projects, some of the most complicated and critical.
- Phase 4 - Finalize: this involved finalizing the most critical migrations for the bank, those for which the slightest failure was unthinkable. We also dealt with the specific case of the datalabs left at the end of the migration.
- Phase 5 - Conclude: the last 20% had some surprises in store that had to be managed in a spirit of program closure to land as planned.
Feedback from Each Phase
Each phase of our Roadmap allowed us to draw the following feedback:
- Phase 1: projects had poor control over their input data; data injections into the cluster were impossible to “scale up” to meet our time/budget constraints. We therefore made a pre-requisite before all migrations a process of identifying/documenting the data to be migrated, allowing for the configuration of data synchronization and ingestion. But above all, these mandatory prerequisites ensured that any ambiguity about the data (what, where) was lifted before launching a migration. It was after this feedback that we launched the two products for ingesting and synchronizing data (see above).
- Phase 2: the first attempt at scaling up was very laborious and revealed that our migration pattern was not yet ready: everything had to be adjusted, made to work, and debugged. And in parallel, we had to continue to anticipate the risks ahead, schedule, and prepare the following phases. The objective was to endure this phase as early as possible to not lose control of the situation: facing these difficulties in phase 3 or 4 with the pressure of the most critical projects for the bank would have posed a major risk to the entire program.
- Phase 3: during this phase, we validated that our migration pattern was now finalized and we were able to address the last side effects on the performance of our products, as well as the finalization of our technical ecosystem (notably the addition of Nifi).
- Phases 4 and 5: the last two phases mainly required a change of mindset to configure the program to conclude despite the last resistances.
Data Governance & Cybersecurity
Let’s conclude this article with two last important aspects: data governance and cybersecurity.
During the program, management mandated that we take advantage of this migration to:
- structure the data into several layers (raw data, normalized data, enriched data), as defined by the Data Architects
- introduce and enforce improved data governance
- ensure the implementation of the data catalog documentation process To do this, we had to introduce a “validation committee” into the migration pattern for all projects; this committee guaranteed compliance with these new constraints but also allowed us to benefit from the feedback of phase 1.
Finally, as one of the challenges of the new cluster was to provide a much higher level of security, we worked hand in hand with the cybersecurity teams. Even though the European DORA directive was not yet an issue at the time, cybersecurity requirements were beginning to become central, and we had to ensure that all our deliverables (processes and tools) were perfectly compliant on the Cyber side.
Checklist: The Keys to a Successful Migration
To finish, I offer you this checklist of points to verify if you have to manage a migration program:
- ✅ Establish a vision for the migration, broken down into phases, to pace all your work.
- ✅ Document your migration pattern and present it to each project so that all stakeholders understand what each migration will entail.
- ✅ Do not overestimate the projects’ knowledge of their data.
- ✅ Be transparent and honest with your teams and the projects about difficulties or problems that are still unsolved.
- ✅ Choose the right timing to force a real scale-up.
- ✅ Identify at the beginning of the migration the products that could fail you.
- ✅ You work for the projects, the projects do not work for you.
Conclusion: To Migrate is to Transform
I hope this journey into the heart of a Big Data cluster migration has enlightened you on some issues that might be underestimated. And if you are working on cloud migrations, some of the aspects covered may undoubtedly help you.
I cannot end this article without warmly thanking all my colleagues who worked with me on this migration, both in the migration team itself, and in the infrastructure teams, project teams, and management teams. They are so numerous that I cannot name them all. But the success of this migration, which kept us intensely busy for almost 2 years, was possible thanks to them 🙏
Feel free to share your Big Data migration experiences in the comments.
And long live the Lucid Cluster!
Salvatore Russo