
From raw code to global architecture: nSens, my R&D lab in the pre-AI era
In my day-to-day life as an IT and Data Project Director, I spend most of my time mediating, coordinating, and ensuring that solutions deliver real business value. But a few years ago, I felt a visceral need to dive back into the nuts and bolts to tackle real technical puzzles.
nSens was born from this desire: a personal project developed in my free time, a two-year engineering adventure that concluded well before the emergence of the LLMs we know today. It was a different time. A time when you couldn’t ask an AI to generate a boilerplate or fix a complex bug in a second. You had to search, fail, and understand the deep inner workings of the web by yourself.
Code speaks louder than words: the entire source code for this personal project is open and available on my GitHub.
The concept: an attempt to map complex knowledge
The initial frustration was simple: browsing the web, from Wikipedia to ArXiv research repositories, felt too linear and fragmented. I wanted to create a tool capable of capturing “atoms” of knowledge to organize them into interconnected “knowbooks” (knowledge notebooks).
To bring this vision to life, I had to design an end-to-end platform. It wasn’t a client project, but my own sandbox to test my skills in full-stack architecture and data engineering.
Getting my hands dirty: building a stack “without a safety net” to understand every gear
At the time, I made the radical choice to build every brick by hand. The backend used Express.js with TypeScript and TypeORM. I initially started with SQLite for simplicity, before migrating to PostgreSQL.
The MobX mindset and mastering the Frontend
On the frontend side, I used Next.js. For state management, a Tech Lead friend pointed me toward MobX. It was a revelation. Far from the sometimes superfluous complexity of Redux, MobX forced me to think in terms of observables and structured stores (RootStore, UIStore, GraphStore). Understanding how to synchronize the interface with asynchronous data without today’s assistance tools was a difficult learning curve, but one that allows me today to debug any modern application.
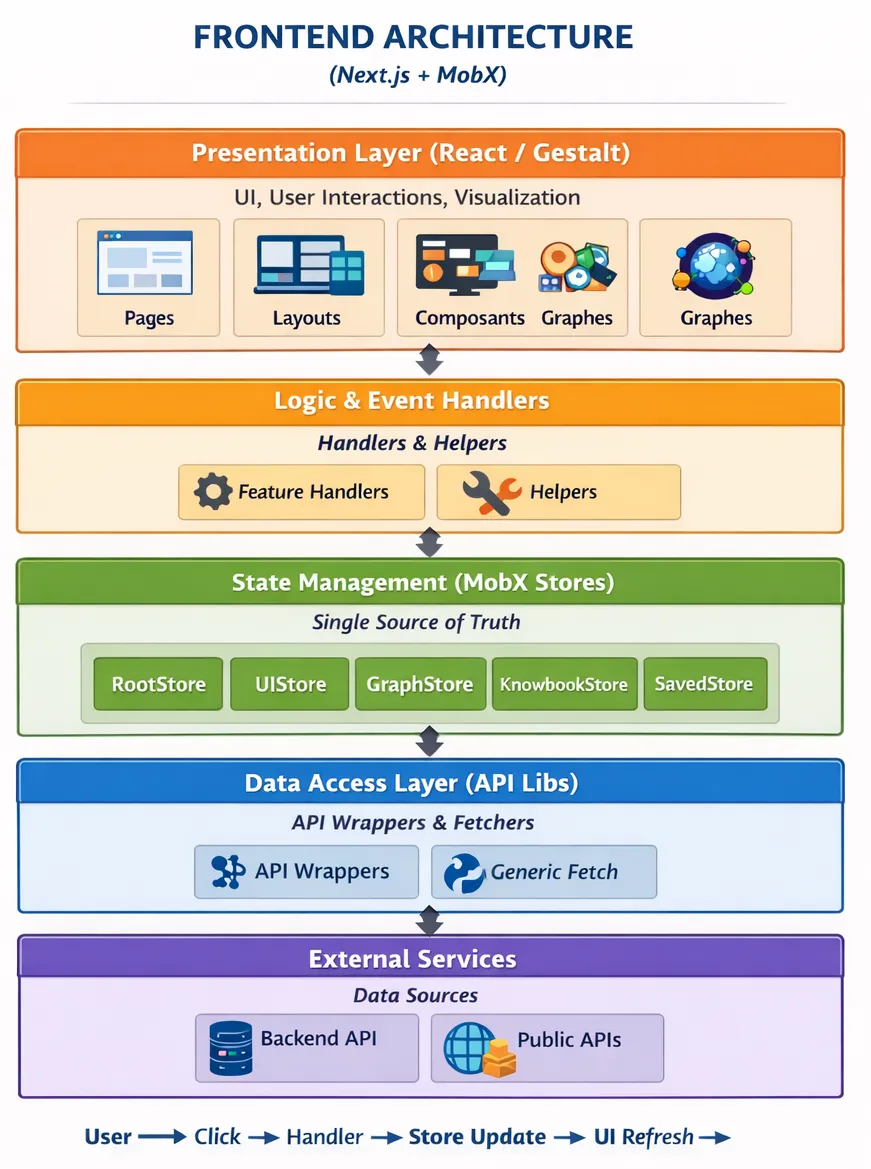
Next.js and SSR: when the documentation becomes your best teacher
Choosing Next.js for the frontend also meant embracing Server-Side Rendering and the entire philosophy that comes with it. The official Next.js documentation is, in that regard, a model of its kind: clear, progressive, and well-illustrated with examples. It allowed me to grasp the fundamentals without having to dig through dozens of scattered sources.
But understanding SSR in theory and taming it in practice are two very different things. Some of nSens’ knowledge notebooks had to be pre-rendered server-side, particularly pre-configured selections like “top of the year” — knowbooks built from calls to Wikipedia, ArXiv, or Wikidata at page generation time, using getStaticProps and getServerSideProps. Knowing where and when to fetch data within the Next.js lifecycle, and understanding what runs on the server versus what belongs to the client, was far from obvious.
This architectural complexity stacked on top of everything else: managing asynchronous logic, making the Next.js backend coexist with my Express API, and keeping it all in sync with the MobX stores on the client side. The result was a layered system where every interaction demanded a precise understanding. In hindsight, it was exactly that friction that made me far more comfortable with modern frameworks — knowing what is really happening behind a use client directive or an SSR call is a mental model you simply never lose.
”Homemade” localization: understanding rather than consuming
One of the project’s unique features was its multilingual aspect (French, English, Italian). Instead of using standard libraries like i18next, I implemented my own localization system. Each language was a massive TypeScript object that I injected into the application. It was artisanal, sometimes tedious, but it allowed me to understand exactly how the interface reacted to context changes. Today, when I integrate a third-party library, I know exactly what is happening under the hood.
Data engineering: taming the web’s heterogeneity
The core of nSens lay in its ability to communicate with heterogeneous APIs. I spent nights coding connectors for Wikipedia, Wikidata (in SPARQL), ArXiv (in XML), and Google Books.
Without AI to explain the sometimes obscure response structures of these services, I had to learn to dissect every payload, manage complex network errors, and format the data to fit into my relational graphs coded with D3.js. This manual work of extracting, cleaning, and formatting raw data was my best teacher…
Ops experimentation: knowing how to balance technical curiosity and ROI
Towards the end of the project, I wanted to explore the world of Ops. I embarked on an exciting experiment using HashiCorp Nomad and Consul to orchestrate my containers on personal servers.
Technically, it was fascinating to see how an application could be distributed. However, in hindsight, it was a disproportionate undertaking for a solo project. I ended up abandoning this complex infrastructure for production, preferring the simplicity of a classic server. This is a fundamental architectural lesson that I apply today with my clients: technology must serve the business, not the developer’s ego. Knowing when to say “stop” to over-engineering is what guarantees a project’s ROI.
What I would do differently today
The way I look at this code today is full of pragmatism. If I had to architect this system for a client today:
- Standardization & Time-to-market: I would use well-known libraries for i18n (and other commodities) to focus solely on business logic.
- Focus on value (MVP): I would spend less time reinventing the UI (like my attempt at a circular interface) to concentrate on pure usage value. Selling a solution that works is better than a perfection that never sees the light of day.
- AI integration: today, this painstaking work on API connectors would be drastically accelerated and enriched by LLM pipelines.
Conclusion: the value of a hybrid profile
Today, nSens is on hold, but its code (still available on my GitHub) remains for me the proof of an era where we learned by breaking a sweat. This builder’s experience has undoubtedly become rare today, as the temptation to delegate global thinking to an LLM is so strong.
Yet, this meticulous construction gave me an understanding of systems that theory alone cannot replace. Building on this learning, I continue my technical explorations today through new personal projects, specifically oriented towards Machine Learning. The difference is that I now fully integrate LLMs into my development process to code faster, experiment more easily, and push my architectures much further.
It is a new approach to technical creation — fascinating and highly effective — that I will have the opportunity to detail in future articles.
Salvatore Russo