
Retour d’expérience sur une migration Big Data d’envergure

Il y a quelques années, chez Société Générale, j’ai eu l’opportunité de piloter un programme de migration stratégique : déplacer plus de 100 applications et datalabs d’un cluster Big Data Legacy vers une nouvelle plateforme, plus moderne, plus automatisée et plus sécurisée… sans jamais interrompre la production. Mon périmètre était celui des directions centrales: conformité, risques opérationnels et de crédit, liquidité, finance, référentiels groupe, RH.
Aujourd’hui, je partage avec vous les enseignements clés de cette aventure, en espérant qu’ils vous inspireront pour vos propres projets de migration, notamment vers le Cloud.
Défi #1 : cracker le sujet des données
Le premier défi important était d’avoir une vision limpide sur comment appréhender la disponibilité des données, aussi bien pour les équipes internes que pour les projets clients. Nous avons considéré dans un premier temps des approches ciblées, comme par exemple:
- une intervention chirurgicale en imaginant mettre à disposition la bonne donnée sur le bon cluster pour la bonne application au bon moment…
- identifier des “grappes de projets” utilisant un même ensemble de données, l’ordonnancement de ces grappes permettant de constituer notre plan de migration
Mais ces deux approches sont immédiatement apparues beaucoup trop compliquées et donc risquées au regard de nos contraintes opérationnelles. Ainsi, nous avons préféré l’approche suivante:
- faire en sorte que les données soient en permanence disponibles sur les deux clusters, tout le temps, pour tous les consommateurs habilités
- déplacer ainsi ces contraintes de la Data sur la dimension technique sans les faire peser sur l’organisation et la gouvernance du programme: les projets gardaient alors une liberté plus grande pour choisir leur timing de migration indépendamment du planning de leurs fournisseurs de données.
Pour ce faire, nous avons rapidement lancé par anticipation un produit visant à rendre notre base technique de synchronisation plus flexible, plus scalable et surtout facilement utilisable à grande échelle par les équipes de migration, sans nécessiter d’interventions bas niveau coté infrastructure.
Défi #2 : Une migration agile et outillée
Nous avons dès le début du programme adopté quelques principes du développement logiciel moderne:
- mettre l’agilité au cœur de l’équipe de migration, englobée dans une organisation de programme plus standard.
- identifier des produits capables d’évoluer en mode “fail fast” et poussant le plus loin possible l’automatisation et la standardisation. Ceci afin de nous assurer d’avoir des produits complètement robustes au moment du passage à l’échelle et traitement des projets les plus critiques.
Plus concrètement, voici comment ces deux dimensions étaient implémentées.
Pour la première, l’équipe de migration était organisée en Scrum avec un sprint d’une semaine, une backlog formalisée évidemment, sous contrôle lors des Sprints planning et avec des boucles de rétroaction rapides grâce aux démos et aux rétrospectives hebdomadaires. Ajouté à ce dispositif agile, nous avions des comités opérationnels hebdomadaires avec les projets et des comités de pilotage avec la direction: ces instances nous permettaient de garder un lien constant et étroit avec les nombreuses parties prenantes.
Pour la deuxième, nous développions les produits suivants (le BUILD en parallèle du RUN des migrations):
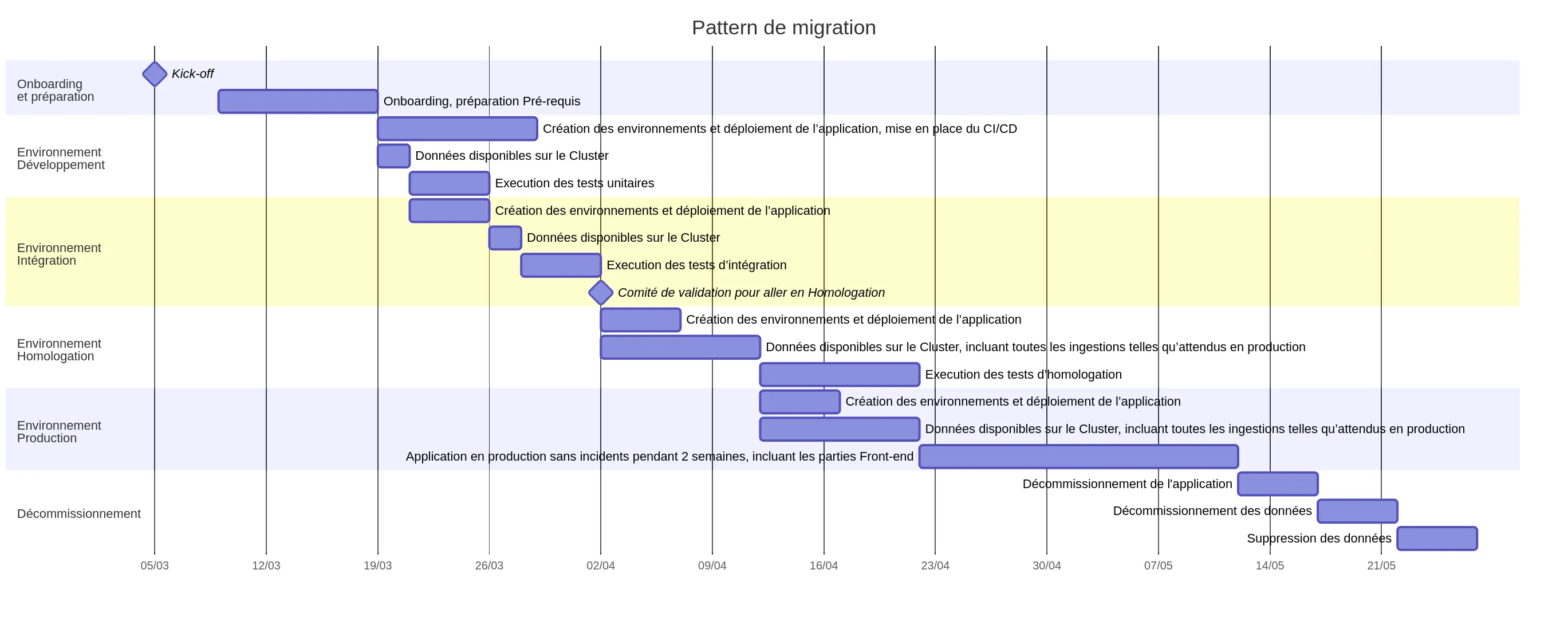
- un produit constitué du pattern de migration (dont le diagramme de Gantt est représenté ci-dessous) incluant ses livrables associés: documentation, sensibilisation d’onboarding, outillage technique d’automatisation, etc…
- un produit, confié à une équipe indépendante, pour industrialiser et sécuriser les synchronisations de données entre clusters et environnements (comme déjà évoqué)
- un produit dédié à l’injection des données (dont le détail technique sort du cadre de cet article)
Roadmap de migrations en 5 phases
Côté pilotage de programme, nous avons organisé notre roadmap de migrations en 5 phases, définies en fonction de la typologie (et des contraintes) des projets, telles que décrites ci-dessous:
- phase 1 - Tester le Proof of Concept: valider notre pattern de migration et valider le bon fonctionnement du nouveau Cluster en production. La migration du premier projet, projet relativement modeste mais utilisant plus d’une vingtaine de sources différentes de données, a permis d’atteindre nos objectifs de cette phase.
- phase 2 - Passer à l’échelle: migrer plusieurs gros projets complexes et mobilisant un maximum de composants techniques externes au cluster Big Data (infrastructures Talend, serveurs edges autour du Cluster, bases de données externes avec beaucoup de flux à ouvrir, etc…). Nous pouvions ainsi apprécier notre capacité à passer à l’échelle et finaliser notre pattern de migration in vivo.
- phase 3 - Délivrer: pendant cette phase, nous avons tiré bénéfice des phases précédentes migrant plusieurs dizaines de projets suivant nos prédictions, incluant tous types de projets, certains des plus compliqués et critiques.
- phase 4 - Finaliser : il s’agissait alors de finaliser les migrations les plus critiques pour la banque, celles pour lesquelles la moindre défaillance était inenvisageable. Nous avons aussi à ce moment traité le cas spécifique des datalabs laissés en fin de migration.
- phase 5 - Conclure : les derniers 20% nous ont réservé des surprises qu’il a fallu gérer dans un esprit de clôture de programme pour atterrir comme prévu.
Retour d’expérience de chaque phase
Chaque phase de notre Roadmap nous a permis de dégager le retour d’expérience suivant:
- phase 1 : les projets maîtrisaient mal leurs données d’entrée, les injections de données dans le cluster étaient en l’état impossible à “passer à l’échelle” pour tenir nos contraintes de temps/budget. Nous avons donc mis en pré-requis avant toutes les migrations un process d’identification/documentation des données à migrer permettant de configurer la synchronisation et l’ingestion des données. Mais surtout, ces pré-requis obligatoires permettaient de garantir que toute ambiguïté sur les données (quoi, où) était levée avant de lancer une migration. C’est à l’issu de ce REX que nous avons lancé les deux produits ingérant et synchronisant les données (voir ci-dessus).
- phase 2 : le premier passage à l’échelle a été très laborieux et a révélé que notre pattern de migration n’était pas encore au point: il a fallu tout régler, tout faire fonctionner, tout debugger. Et en parallèle, continuer à anticiper les risques devant nous, ordonnancer et préparer les phases suivantes. L’objectif était de subir cette phase le plus tôt possible pour ne pas perdre le contrôle de la situation: subir ces difficultés en phase 3 ou 4 avec la pression des projets les plus critiques pour la banque aurait fait courir un risque majeur à tout le programme.
- phase 3 : pendant cette phase, nous avons validé que notre pattern de migration était maintenant finalisé et nous avons pu traiter les derniers effets de bord sur les performances de nos produits, ainsi que la finalisation de notre écosystème technique (notamment ajout de Nifi).
- phase 4 et 5 : les deux dernières phases ont surtout nécessité un changement d’état d’esprit pour configurer le programme à se conclure malgré les dernières résistances.
Gouvernance des données & Cybersécurité
Concluons cet article sur deux derniers aspects importants: la gouvernance des données et la cybersécurité.
La direction a imposé en cours de programme de profiter de cette migration pour:
- structurer les données en plusieurs couches (données brut, données normalisées, données enrichies), telles que définies par les Data Architect
- introduire et faire respecter une gouvernance des données améliorée
- assurer l’implémentation du processus de documentation du catalogue de données Pour ce faire, nous avons dû introduire dans le pattern de migration le “comité de validation” pour tous les projets; ce comité garantissant la conformité à ces nouvelles contraintes mais nous permettant aussi de tirer profit du REX de la phase 1.
Enfin, dans la mesure où l’un des enjeux du nouveau cluster était d’apporter un niveau de sécurité largement supérieur, nous avons travaillé main dans la main avec les équipes de la cybersécurité. Même s’il n’était pas encore question à l’époque de la directive européenne DORA, les exigences de cybersécurité commençaient à devenir centrales et nous devions garantir que toutes nos livraisons (process et outils) étaient parfaitement conformes coté Cyber.
Checklist : les clés d’une migration réussie
Pour finir, je vous propose cette checklist sur les points à vérifier si vous devez piloter un programme de migration:
- ✅ Établir une vision pour la migration, découpée en phase, pour rythmer tous vos travaux.
- ✅ Documentez votre pattern de migration et présentez le à chaque projet pour que toutes les parties prenantes comprenne de quoi chaque migration sera faite.
- ✅ Ne surestimez pas la connaissance des projets de leurs données.
- ✅ Soyez transparent et honnête avec vos équipes et les projets sur les difficultés ou problèmes encore sans solutions.
- ✅ Choisissez le bon timing pour forcer un véritable passage à l’échelle.
- ✅ Identifiez en début de migration les produits qui pourraient vous faire défaut.
- ✅ Vous travaillez pour les projets, ce ne sont pas les projets qui travaillent pour vous.
Conclusion : migrer, c’est transformer
J’espère que ce voyage au cœur de la migration d’un cluster Big Data vous aura éclairé sur certaines problématiques qui pourraient être sous-estimées. Et si vous travaillez plutôt sur des migrations cloud, certains aspects couverts pourront sans doute vous aider.
Je ne peux pas finir cet article sans remercier chaleureusement tous mes collègues qui ont travaillé avec moi sur cette migration, aussi bien dans l’équipe de migration en elle même, que dans les équipes d’infrastructure, dans les équipes projets et les équipes de directions. Ils sont tellement nombreux que je ne peux pas tous les citer. Mais le succès de cette migration, qui nous a mobilisé intensément presque 2 ans, a été possible grâce à eux 🙏
N’hésitez pas à partager en commentaires vos expériences de migrations Big Data.
Et longue vie au Cluster Lucid !
Salvatore Russo