
Du code brut à l'architecture globale : nSens, mon laboratoire R&D à l’ère pré-IA
Dans mon quotidien de Directeur de Projet IT et Data, je passe l’essentiel de mon temps à arbitrer, coordonner et m’assurer que les solutions délivrent une vraie valeur métier. Mais il y a quelques années, j’ai ressenti le besoin viscéral de replonger dans la “matière” pour affronter de vrais casse-têtes techniques.
nSens est né de cette envie : un projet personnel développé sur mon temps libre, une aventure d’ingénierie de deux ans qui s’est achevée bien avant l’émergence des LLM que nous connaissons aujourd’hui. C’était un autre temps. Un temps où l’on ne demandait pas à une IA de générer un boilerplate ou de corriger un bug complexe en une seconde. Il fallait chercher, échouer, et comprendre par soi-même les rouages profonds du web.
Le code plutôt que des discours: l’intégralité du code source de ce projet personnel est ouvert et disponible sur mon GitHub.
Le concept : une tentative de cartographier la connaissance complexe
La frustration initiale était simple : la navigation sur le web, de Wikipedia aux dépôts de recherche ArXiv, me semblait trop linéaire et fragmentée. Je voulais créer un outil capable de capturer des “atomes” de savoir pour les organiser dans des “knowbooks” (carnets de connaissance) interconnectés.
Pour donner vie à cette vision, j’ai dû concevoir une plateforme complète de bout en bout. Ce n’était pas un projet client, mais mon propre bac à sable pour éprouver mes compétences en architecture full-stack et en ingénierie de la donnée.
Les mains dans le cambouis : construire une stack “sans filets” pour comprendre chaque rouage
À l’époque, j’ai fait le choix radical de construire chaque brique à la main. Le backend utilisait Express.js avec TypeScript et TypeORM. J’ai d’abord commencé sur SQLite pour la simplicité, avant de migrer vers PostgreSQL.
L’état d’esprit MobX et la maîtrise du Frontend
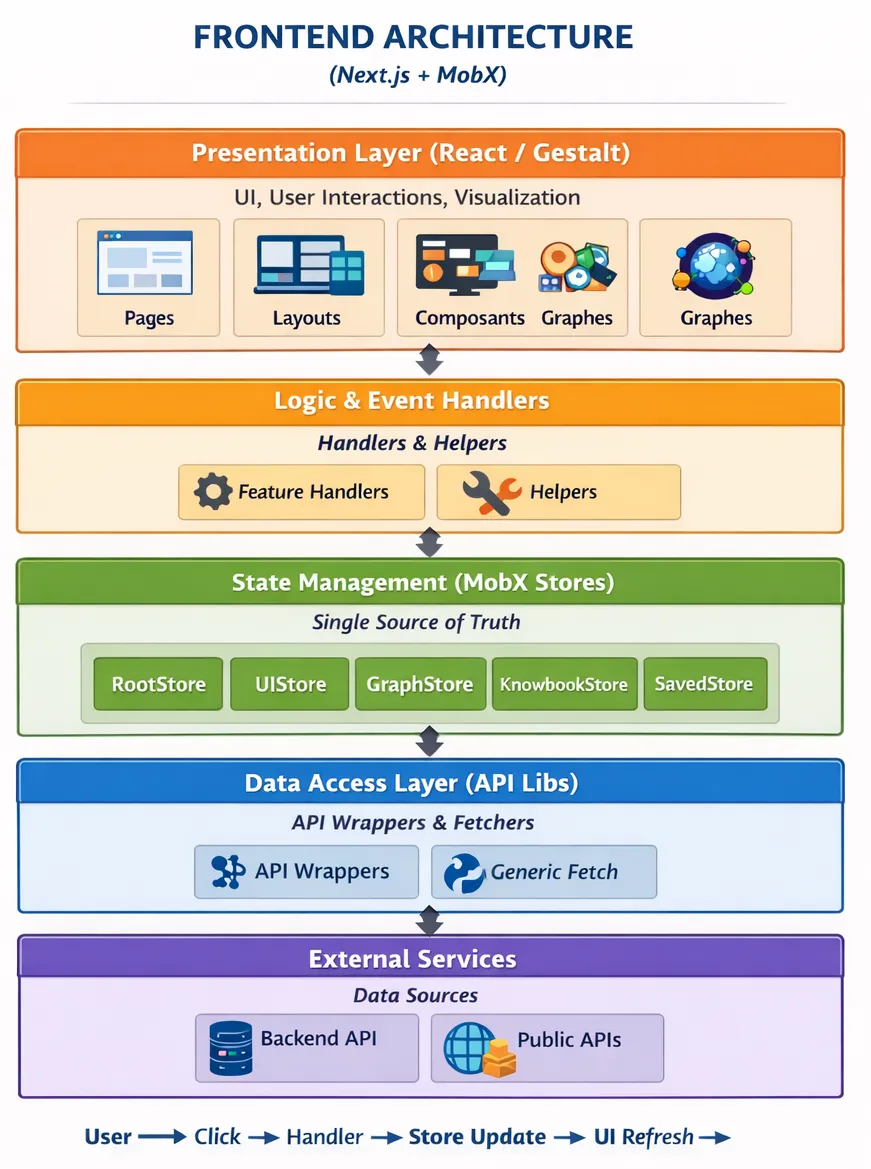
Côté frontend, j’utilisais Next.js. Pour la gestion d’état, c’est un ami Tech Lead qui m’a aiguillé vers MobX. Ce fut une révélation. Loin de la complexité parfois superflue de Redux, MobX m’a forcé à réfléchir en termes d’observables et de stores structurés (RootStore, UIStore, GraphStore). Comprendre comment synchroniser l’interface avec des données asynchrones sans les outils d’assistance actuels a été un apprentissage difficile mais qui me permet aujourd’hui de débugger n’importe quelle application moderne.
Next.js et le SSR : quand la documentation devient ton meilleur professeur
Choisir Next.js pour le frontend, c’était aussi choisir d’embrasser le Server-Side Rendering et toute la philosophie qui l’accompagne. La documentation officielle de Next.js est, à ce titre, un modèle du genre : claire, progressive, bien exemplarisée. Elle m’a permis d’en comprendre les fondations sans avoir à fouiller des dizaines de sources disparates.
Mais comprendre le SSR en théorie et le dompter en pratique sont deux choses très différentes. Certains carnets de connaissance de nSens devaient être pré-générés côté serveur, notamment les sélections configurées en amont comme les “tops de l’année” — des knowbooks construits à partir d’appels vers Wikipedia, ArXiv ou Wikidata au moment de la génération de la page, via getStaticProps et getServerSideProps. Savoir où et quand récupérer la donnée dans le cycle de vie de Next.js, comprendre ce qui s’exécute sur le serveur et ce qui appartient au client, n’était pas une évidence.
Cette complexité architecturale s’est additionnée à tout le reste : la gestion de l’asynchrone, la cohabitation du backend Next.js avec mon API Express, et la synchronisation avec les stores MobX côté client. Le tout formait un empilement de couches dont chaque interaction demandait une compréhension fine. Rétrospectivement, c’est précisément cette friction qui m’a rendu beaucoup plus à l’aise avec les frameworks modernes — savoir ce qui se passe vraiment derrière un use client ou un appel SSR, c’est une grille de lecture que l’on ne perd plus.
Une localisation “faite maison” : comprendre plutôt que consommer
L’une des particularités du projet était son aspect multilingue (Français, Anglais, Italien). N’utilisant pas de bibliothèques standard comme i18next, j’ai implémenté mon propre système de localisation. Chaque langue était un objet TypeScript massif que j’injectais dans l’application. C’était artisanal, parfois fastidieux, mais cela m’a permis de comprendre exactement comment l’interface réagissait aux changements de contexte. Aujourd’hui, quand j’intègre une librairie tierce, je sais exactement ce qui se passe sous le capot.
L’ingénierie de la donnée : dompter l’hétérogénéité du web
Le cœur de nSens résidait dans sa capacité à discuter avec des API hétérogènes. J’ai passé des nuits à coder des connecteurs pour Wikipedia, Wikidata (en SPARQL), ArXiv (en XML) et Google Books.
Sans IA pour m’expliquer les structures de réponses parfois obscures de ces services, j’ai dû apprendre à décortiquer chaque payload, à gérer les erreurs réseau complexes et à formater les données pour qu’elles s’intègrent dans mes graphes relationnels codés avec D3.js. Ce travail manuel d’extraction, de nettoyage et de formatage de la donnée brute a été mon meilleur professeur…
L’expérimentation Ops : savoir arbitrer entre curiosité technique et ROI
Sur la fin du projet, j’ai voulu explorer l’univers des Ops. Je me suis lancé dans une expérimentation passionnante avec HashiCorp Nomad et Consul pour l’orchestration de mes conteneurs sur des serveurs personnels.
Techniquement, c’était fascinant de voir comment on pouvait distribuer une application. Cependant, avec le recul, c’était un chantier démesuré pour un projet solo. J’ai fini par renoncer à cette infrastructure complexe pour la mise en production, préférant la simplicité d’un serveur classique. C’est une leçon d’architecture fondamentale que j’applique aujourd’hui avec mes clients : la technologie doit servir le business, pas l’ego du développeur. Savoir dire “stop” à l’over-engineering est ce qui garantit le ROI d’un projet.
Ce que je ferais différemment aujourd’hui
Le regard que je porte aujourd’hui sur ce code est rempli de pragmatisme. Si je devais architecturer ce système aujourd’hui pour un client :
- Standardisation & Time-to-market : j’utiliserais des bibliothèques reconnues pour l’i18n (et autres commodités) pour me concentrer uniquement sur la logique métier.
- Focus sur la valeur (MVP) : je passerais moins de temps à refaire l’UI (comme ma tentative d’interface circulaire) pour me concentrer sur la valeur d’usage pure. Vendre une solution qui marche vaut mieux qu’une perfection qui ne voit jamais le jour.
- L’intégration de l’IA : aujourd’hui, ce travail de fourmi sur les connecteurs API serait drastiquement accéléré et enrichi par des pipelines LLM.
Conclusion : la valeur d’un profil hybride
Aujourd’hui, nSens est à l’arrêt, mais son code (toujours consultable sur mon GitHub) reste pour moi la preuve d’une époque où l’on apprenait par la sueur. Cette expérience de bâtisseur est sans doute devenue rare aujourd’hui, tant la tentation de déléguer la réflexion globale à un LLM est grande.
Pourtant, cette construction minutieuse m’a apporté une compréhension des systèmes que la seule théorie ne remplace pas. Fort de cet apprentissage, je poursuis aujourd’hui ces explorations techniques à travers de nouveaux projets personnels, particulièrement orientés vers le Machine Learning. La différence, c’est que j’intègre désormais pleinement les LLM dans mon processus de développement pour coder plus vite, expérimenter plus facilement et pousser mes architectures beaucoup plus loin.
C’est une nouvelle approche de la création technique, fascinante et redoutablement efficace, que j’aurai l’occasion de détailler dans de prochains articles.
Salvatore Russo